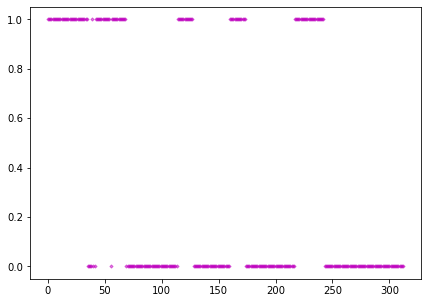
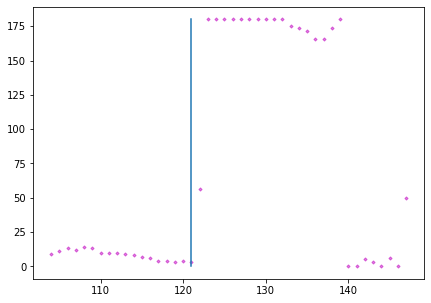
我們使用各種不同的機器學習模型去訓練其判斷擊球方為哪位選手,並將影片上方的選手視為選手A,下方的選手視為選手B。資料筆數為所有影片中的擊球幀共有3269筆資料。變數除了先前透過不同偵測方式所獲取的羽球軌跡(X、Y座標)、人物節點(兩個人、XYZ座標、25個節點)及場地(8個交點的X、Y座標)外,還加上了球與手的距離(羽球和兩位球員的直徑距離),一共有170個變數。而資料中的Y則是需要預測的擊球方。我們將整筆資料拆分成訓練集70%、測試集30%,來進行後續的模型訓練。而我們在訓練中一共採用了XGBoost、SVM(支援向量機)、Perceptron(感知器) 、Decision Tree(決策樹)、Logistic Regression(邏輯斯回歸)、Random Decision Forests(隨機森林),這6種模型進行預測,並使用多數決來決定最終的擊球選手。
| 分類器 | 訓練集準確率 | 測試集準確率 |
| XGBoost | 90.12% | 88.58% |
| SVM(支援向量機) | 96.51% | 95.31% |
| Perceptron(感知器) | 88.02% | 89.09% |
| Decision Tree(決策樹) | 89.72% | 88.58% |
| Logistic Regression(邏輯斯回歸) | 95.32% | 95.41% |
| Random Decision(隨機森林) | 88.46% | 87.36% |
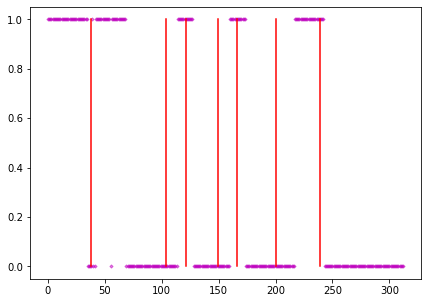
我們使用多數決來決定該球的打擊者,將選手A當作0,選手B當作1。
在決定打擊者時會有兩種狀況。
狀況1:
當6種模型的預測結果有3種以上(不包含3)將其判定為0或是1,而該局的打擊者就會是多的那一方。
狀況2:
當6種模型的預測結果為3:3,各占一半,便使用計算的方式,來決定打擊者,先將所有的模型測試準確率加總除以2,以此數值作為分隔線。
並將1(選手B)的三種準確率加總,若其加總的數值大於分隔線,便判定本球的打擊者為1(選手B)。反之,若該數值加總小於分隔線,則本球的打擊者就會是0(選手A)。
舉例來說,XGBoost、SVM、Perceptron均預測為1,其餘均預測為0。
我們便將3種預測為1的準確率相加,加總的數值為272.98,而全部的準確率加總除以2為272.165,因預測為1的值大於分隔線值,於是該球的打擊者判定為1(選手B)。